安装OpenVINO2022全新C++ SDK使用详解
时间:2022-05-08 来源:咖咖下载
安装OpenVINO2022.1
2022版本的安装包跟之前的不一样地方包括:
-OpenCV部分不在默认安装包中-Dev Tools 跟 Runtime安装方式不同-Dev Tools包模型转换器跟其它开发组件-Runtime主要负责模型推理,支持Python跟C++
在intel官方下载页面选择如下:
下载之后点击安装,出现的第一个画面如下:
点击【Continue】
选择第一种,推荐安装方式,点击【Continue】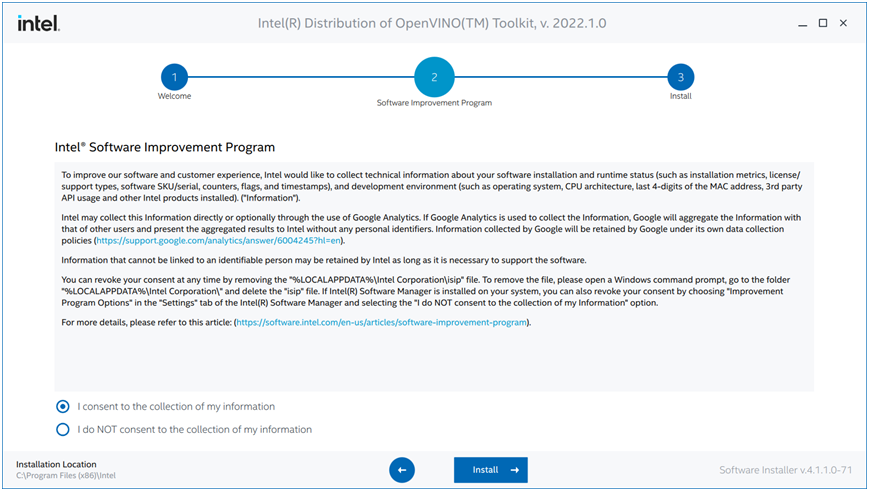
点击【Install】就会开始正式安装过程!这个过程中如果你没有安装VS2019会有一个警告出现,直接选择忽视,继续安装即可!因为我VS2017。
配置OpenVINO2022开发环境
1. 包含目录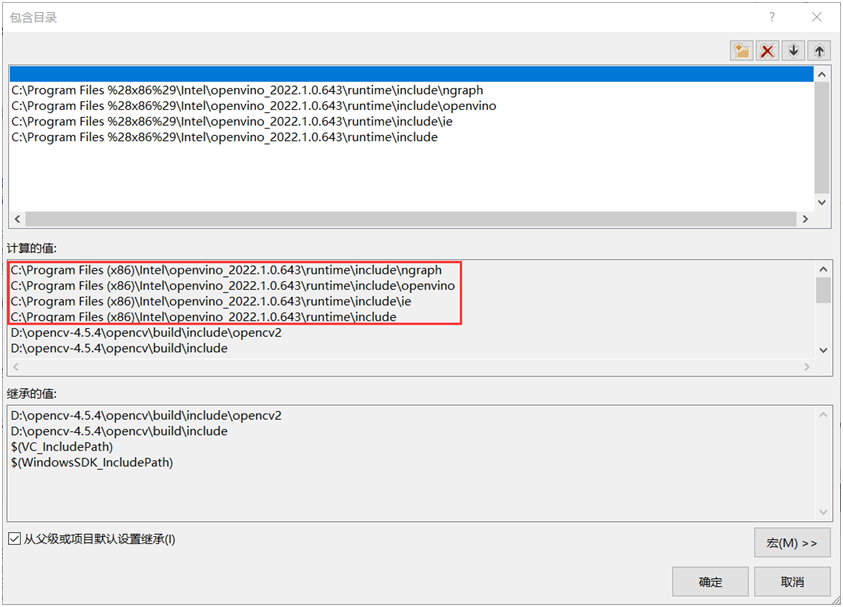
2. 库目录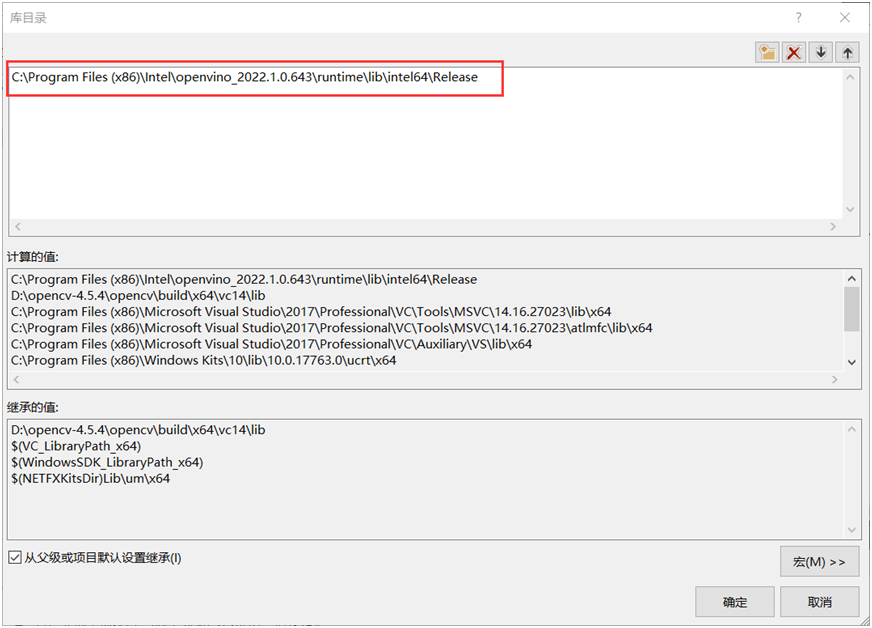
3. 附加依赖项添加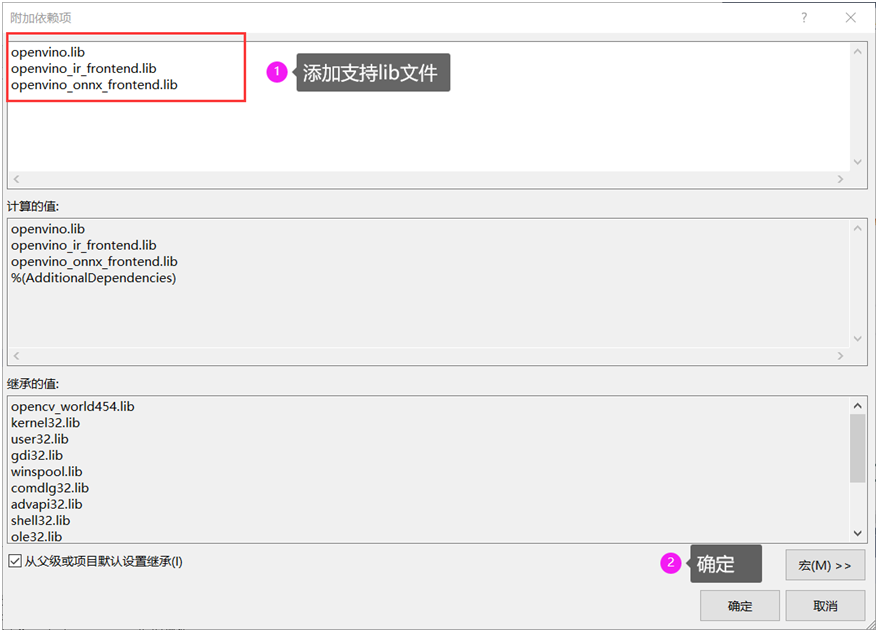
这样就完成了
最后配置好环境变量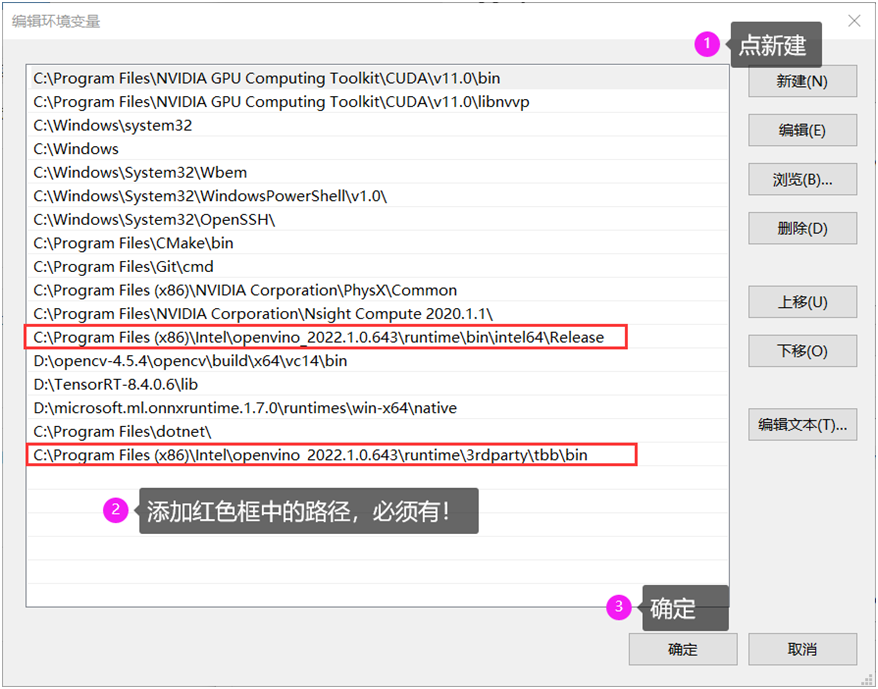
然后重启VS2017,执行如下代码测试:
#include <openvino/openvino.hpp>
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
int main(int argc, char** argv) {
// 创建IE插件, 查询支持硬件设备
ov::Core ie;
vector<string> availableDevices = ie.get_available_devices();
for (int i = 0; i < availableDevices.size(); i++) {
printf("supported device name : %s \n", availableDevices[i].c_str());
}
return 0;
}
运行结果如下: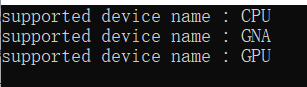
最新SDK使用解析
01
模型加载
ov::CompiledModel compiled_model = ie.compile_model(onnx_path, "AUTO");ov::InferRequest infer_request = compiled_model.create_infer_request();
02
获取输入
ov::Tensor input_tensor = infer_request.get_input_tensor();ov::Shape tensor_shape = input_tensor.get_shape();03
把图像填充输入tensor数据
size_t num_channels = tensor_shape[1];
size_t h = tensor_shape[2];
size_t w = tensor_shape[3];
Mat blob_image;
resize(src, blob_image, Size(w, h));
blob_image.convertTo(blob_image, CV_32F);
blob_image = blob_image / 255.0;
// NCHW
float* image_data = input_tensor.data();
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
image_data[row * w + col] = blob_image.at(row, col);
}
}
4
推理跟后处理
// 执行预测
infer_request.infer();
// 获取输出数据
auto output_tensor = infer_request.get_output_tensor();
const float* detection = (float*)output_tensor.data();
很容易获取输出的数据,有了输出数据,下面的解析就会简单很多,可以说相比之前代码,这里是一步获取输出数据。

最后总结
01
输入与输出获取
ov::InferRequest支持直接获取输入跟输出tensor,分别对应方法是
get_input_tensor()get_output_tensor()get_tensor(name)02
C4996错误
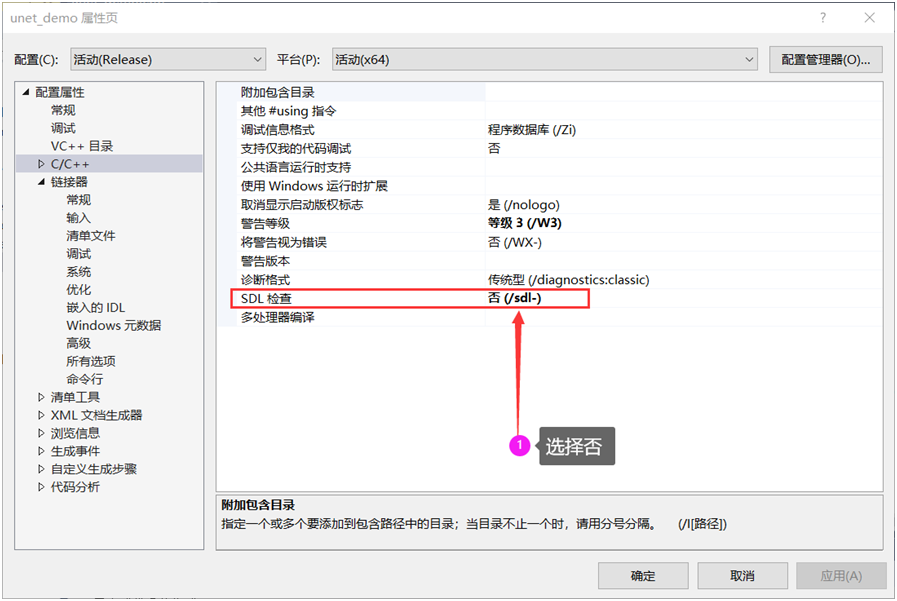
03
代码行变动
04
Python版本支持
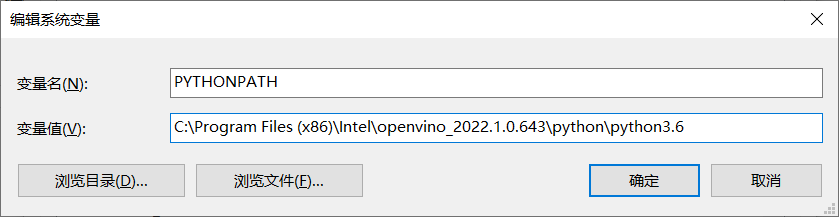
记得输入的路径最后版本号一定要跟系统安装的python版本号保持一致。测试:
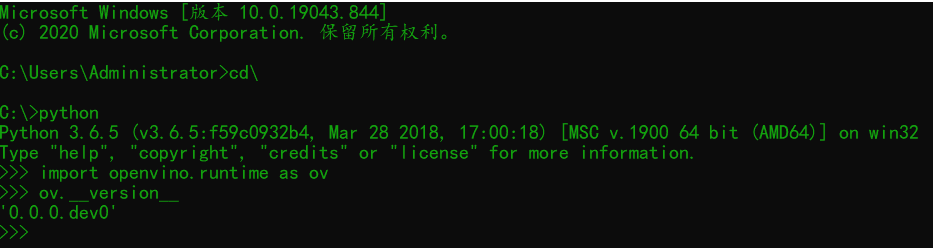
相关内容
-
-
-
2022/05/08
VS2017 遇到 DolphinDB如何编译 C++ API 动态库 -
2022/05/08
安装OpenVINO2022全新C++ SDK使用详解 -
2022/05/08
Win10:C++ (VS 2017)下LibCurl的配置和使用
-
-
Visual Studio 2017(VS2017)Visual Studio开发工具集软件下载附安装指导
【软件分类】:Visual Studio(开发工具集)【软件名称】:Visual Studio 2017【语言环境】:简体中文 【安装环境】:Window安装步骤1. 安装前注意一下自己电脑的IE浏览器是不是10 版...
2022/05/08
-
VC++ 6.0开发编程软件下载附安装教程
【软件分类】:开发编程【软件名称】:VC++6.0【语言环境】:简体中文 【安装环境】:Windows安装步骤1.右击软件压缩包,选择解压到“VC6.0(32&6bit)”选项 2.双击Setup...
2022/05/08
系统教程栏目
栏目热门教程
人气教程排行
- 1 MacOS怎么使用分区加密功能?MacOS硬盘分区加密功能的使用办法
- 2 Win10桌面图标无法使用该怎么处理?这个办法帮你解决问题
- 3 小爱音箱怎么连接wifi?小爱音箱连接wifi的办法
- 4 Win10打开程序总会跳转到应用商店该怎么办
- 5 Win10 2004开机黑屏该怎么处理?开机黑屏的处理办法
- 6 Win8怎么加快桌面图标刷新速度?提高图标刷新速度的办法解析
- 7 UOS统一操作系统怎么获取root权限?UOS获取root权限的办法
- 8 R7 1800X游戏对决i7-6900K:结果出乎意料
- 9 怎么查看电脑配置?查看电脑配置的具体步骤
- 10 Win7系统连接耳麦不能说话该怎么处理 耳麦不能说话该怎么解决
站长推荐
热门系统下载
- 1 深度技术Ghost Win7 SP1 x64 v2021全新系统
- 2 电脑公司Ghost Win10 64位装机版 v2020.06
- 3 新萝卜家园Ghost Win7 SP1 x64 v2021全新系统
- 4 GHOST XP SP3 装机专业版 v2021最新版
- 5 雨林木风 Ghost Win7 SP1 x64 v2021全新系统
- 6 电脑公司 Ghost Win7 SP1 X64 V2021全新系统
- 7 雨林木风 Ghost Win7 SP1 x86 v2021全新系统
- 8 深度技术Ghost Win7 SP1 64位 v2021全新系统
- 9 番茄花园 Ghost Win7 SP1 X64 v2021全新系统
- 10 深度技术Ghost Win7 SP1 32位 v2021全新系统